
Cognitive Assembly Lines
From context engineering to “enterprise as code,” manufacturing logic comes to knowledge work

You could call it the paradox of enterprise AI adoption: while AI keeps getting smarter at astonishing speed, the challenge of deploying real-world AI applications doesn’t seem to be getting any easier. On reflection, though, maybe we shouldn’t be surprised. After all, we all know that simply hiring a bunch of brilliant people doesn’t magically solve business problems. The same appears to hold true for AI.
At this point, unlocking value from AI is less a matter of smarter models—the models are more than smart enough already—and more a question of how to integrate models with information and with a network of human and virtual collaborators. Techniques for effective integration are just beginning to emerge, notably context engineering for integrating information and multi-agent architectures for integrating AI with virtual collaborators.
Integrating AI with human collaborators remains something of a black art. In practical terms, it’s a user experience and organizational work-design challenge: where agents sit in workflows, what they’re allowed to touch, when they must escalate, how outputs are reviewed, and who owns the results.
In this article, I’ll highlight some recent advances in AI capabilities, dive into the details of emerging context engineering infrastructure (illustrated with a wealth management use case), and close with work-design lessons drawn from the Industrial Revolution. In the New Year, I’ll turn to the emerging science of architecting multi-agent systems.
The IQ boom
AI models have such extraordinary linguistic and persuasive capabilities that it’s hard to evaluate their intelligence based on day-to-day interactions. Nevertheless, more rigorous evaluation techniques show that the latest models are indeed smarter, and smarter in ways that matter for practical business applications.
On December 11, OpenAI introduced GPT-5.2. To measure the performance of AI models, OpenAI invested substantial resources in developing their GDPval benchmark, a set of tasks developed by industry experts to be representative of knowledge work performed by professionals in 44 different occupations. (I wrote about GDPval in From Workslop to Workflow: What AI Skeptics Get Wrong.) To score a model against the benchmark, experts compare the model’s output for each task against work produced by a human expert. The score is the percentage of tasks for which the model output is judged superior or equivalent to the human work product.
GPT-5.2’s score on GDPval is 70.9%, compared to 38.8% for GPT-5. That means human experts only outperformed GPT-5.2 on about three out of ten tasks. And these are not simple tasks! Here are a few examples (full text of the task prompts is available here):
Prepare an individual tax return (form 1040)
Create test questions for an audit of mortgage loans that trigger certain regulatory provisions (50 U.S. Code §3937 and §3919)
Analyze long-term cost implications based on quotes received from multiple vendors
The implication is that for well-specified professional tasks, you should usually default to a frontier model for the first draft, then apply human review and refinement as needed. It’ll be dramatically faster, too.
Focusing specifically on financial analysis, new research finds that frontier models (e.g., GPT-5, Gemini 3.0 Pro) perform very well on the Chartered Financial Analyst (CFA) exams. The exams range in difficulty from Level I (foundational knowledge) to Level III (complex synthesis and portfolio construction). The table below summarizes some of the results. It seems likely that GPT-5.2 would perform better than GPT-5.
Context, assembled
So how do we plug this incredibly powerful intellect into our organizations? No one really knows, yet. In fairness, it took a while to figure out how to plug humans into organizations, and we still do that imperfectly at best. But a couple of things are becoming clear.
First, although AI models are extremely smart, they still experience information overload. Hence the critical importance of context engineering: marshaling relevant instructions, data, resources, and software tools to orient the AI and help it stay focused on the most important and relevant aspects of its task. (For more background on context engineering, see When Generic AI Falls Short: Why Frontier AI Models Underperform, and How Context Engineering Closes the Gap.)
Context engineering is still more art than science, but OpenAI’s GDPval task definitions demonstrate a straightforward pattern that works. They include clear instructions and relevant documents, much as a veteran employee might prepare when delegating a task to a brilliant but inexperienced new hire. Of course, context engineering gets trickier when AI agents need to work with large volumes of information to do their jobs. Such situations arise often in complex projects and business relationships.
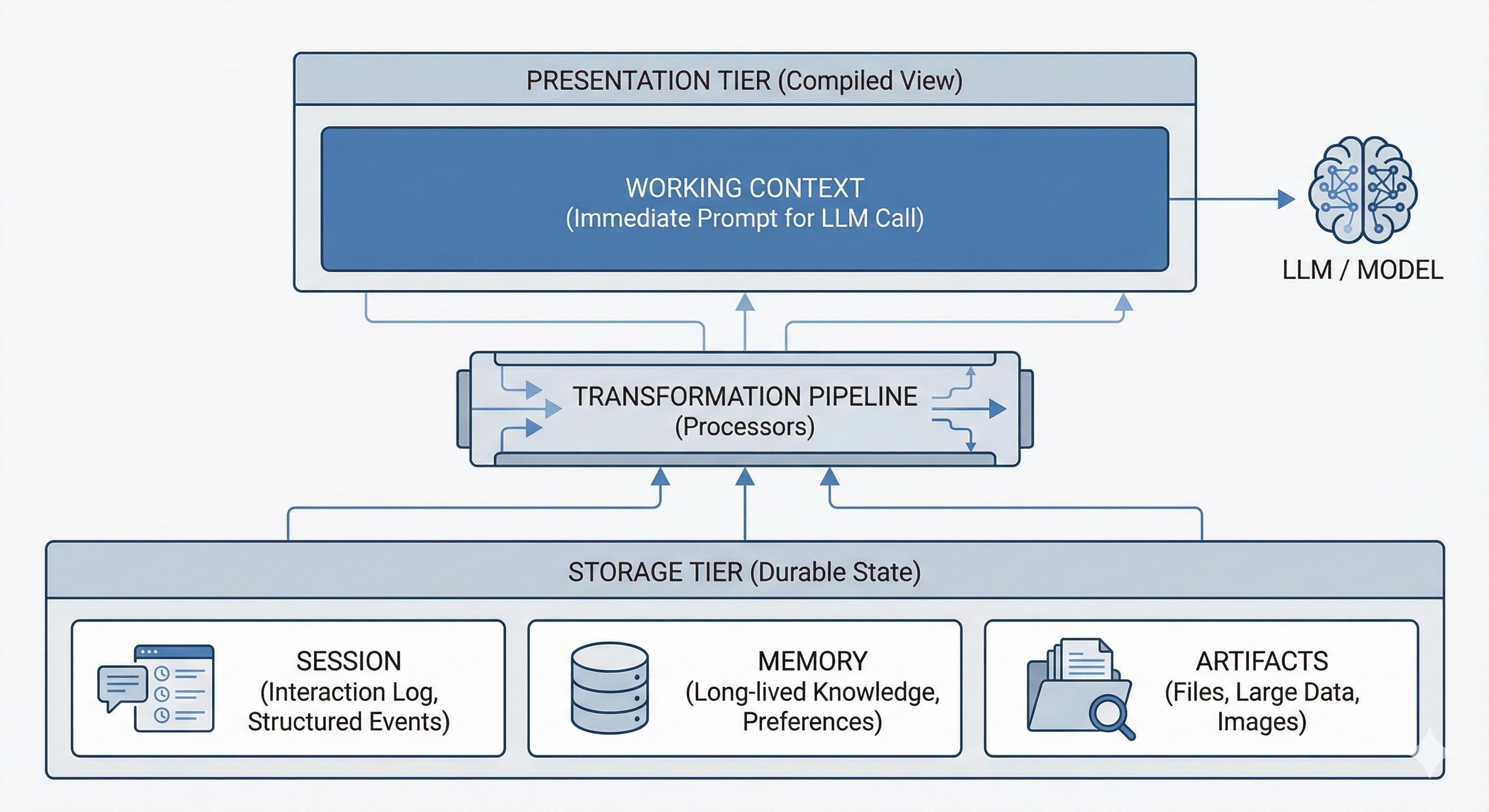
This recent Google blog post describes a more sophisticated method for context engineering, implemented in Google’s Agent Development Kit. This approach, shown in the figure below, distinguishes three different kinds of information resources that the AI agent may need to access.
Session data is a historical record of the agent’s conversation: the prompts given to the agent and its responses.
Memory is a searchable repository of knowledge relevant to the agent’s work.
Artifacts are documents, images, videos, and other digital files.
Software engineers develop specialized context processors that operate on the session, memory, and artifacts to synthesize a package of information relevant to a specific situation. These context processors are chained together into a context generation pipeline which yields the working context provided to the AI to guide its next round of inference.
A worked example: wealth management
To get a clearer understanding of Google’s context engineering framework, let’s consider a specific example from the wealth management industry. Suppose your firm is building an AI assistant to support financial advisors who serve high-net-worth clients. In this scenario, memory might hold a database of portfolio holdings and client financial plan parameters, while artifacts could include the firm’s policy manuals and house views as well as third-party research reports, fund prospectuses, earnings call transcripts, and so on. The session would capture current conversation state, such as specific clients or securities that the advisor is focusing on.
Taken together, the session, memory, and artifacts hold far more information than the agent can handle at any given moment. Even if the entire database of portfolio holdings could fit into the AI model’s context window, the AI would likely get confused and lost in the details. The solution is to generate a targeted working context by using context processors to selectively extract, summarize, and synthesize relevant data from the underlying information sources. In this wealth management use case, there might be specific context processors such as the following:
Client Context Processor retrieves information about a specific client, such as their address, age, immediate family members, risk tolerance, and financial goals.
Portfolio Context Processor retrieves information about a client’s portfolio holdings and historical performance.
Equity Context Processor retrieves information about one or more equities, including links to recent filings and relevant research reports.
Depending on information in the session and the input from the advisor, these context processors may function differently. For example, if session variables indicate that the conversation is currently focused on a specific client, the Portfolio Context Processor would retrieve information about that client’s portfolio. However, if the advisor has been scrutinizing the latest earnings release from Microsoft without reference to a particular client, the Portfolio Context Processor might instead retrieve information about portfolios with concentrated holdings of that equity.
While the processors push relevant information into the working context automatically, the framework also provides tools that the AI agent can use proactively to shape its context by pulling information from memory and documents from the artifacts repository. So if the advisor asks the agent a question about a client’s financial plan or about analyst views on Microsoft Copilot, the agent can invoke tools to load this information into its working context.
This structured approach to context management makes it easier to observe, analyze, and refine the way that relevant information flows to the AI agent, reducing information overload, decreasing hallucination, and improving overall task performance.
Genius needs a job description
As the above example shows, effective context engineering requires a precise understanding of the tasks that agents need to perform and the information they require to be successful. The implication for agentic automation in the enterprise is clear: before you deploy agents, you need to rigorously specify their work. In a recent article, the Boston Consulting Group characterized this imperative as “enterprise as code”:
At its core, enterprise as code is about explicitly defining how a business operates by capturing the implicit operating model and expressing it as code. This allows both people and systems to understand, test, and improve how organizations run, whether the systems involved are automation frameworks, analytical tools, or AI agents.
Embracing this shift requires organizations to move from intuition to specification. Rather than relying on an indefinable sense of how things work, they capture the logic behind operations and decisions in forms that both people and systems can act on and evolve over time.
AI extends mass production paradigms to knowledge work. “Enterprise as code” is a twenty-first century version of scientific management, the early twentieth-century movement that sought to optimize manual labor by studying how specific tasks were actually done, defining standard procedures for performing tasks, and then gradually optimizing these procedures based on experiments and analysis. Scientific management and its leading proponent, Frederic Taylor, have been much maligned for reducing human workers to cogs in the machine, perhaps for good reason: scientific management sought to separate thinking (the definition and optimization of how people work) from doing (the execution of tasks in strict conformance with standard procedures.)
Agentic AI brings scientific management to knowledge work. The GDPval and CFA exam benchmarks above show that AI is smart enough to handle just about any professional task, but only when the work has been clearly specified and context engineering has equipped the model with the right information. Humans will need to play the role of Taylorist managers: studying and codifying knowledge work so it can be delegated to AI for execution, then measuring, analyzing, and continuously optimizing the resulting workflows.
This is the real shift. The takeaway isn’t “replace experts.” It’s that for well-specified professional tasks—with clear inputs, clear acceptance criteria, and the right supporting documents—AI can now produce expert-level drafts at dramatically lower latency and cost, especially when paired with human review and accountability. The bottleneck is no longer raw model intelligence; it’s the operating system surrounding the model: context, tools, workflow integration, and governance.
Fortunately, AI does not seem to object to being a cog in the cognitive machine, at least for the time being.
Happy holidays, and best wishes in 2026!
Transitioning assembly line logic to knowledge work requires 'Standardization' first. We need an 'Automatic Kaizen Loop' for prompts.
Couldn't agree more, the point about unlocking value being more about intergration than just smarter models is so spot on and often overlooked. It makes me wonder if the real bottleneck for 'cognitive assembly lines' will always be our own human adaptabilty and how we design interfaces for true collaboration, especially for everyday users.